
The Last Mile Problem: Why General LLMs Can’t Run Your Research Workflow
A technical, workflow-first perspective for institutional finance teams

Every serious investor is running the same experiment right now.
Someone at the desk opens ChatGPT, Gemini, Claude, or Perplexity and types a query that sounds trivial:
“Which NBFCs mentioned write-offs in their Q2 FY26 disclosures?”
The answer arrives instantly.
Clean bullets. Confident phrasing. Perfect fluency.
For a moment, it feels like the morning meeting just automated itself.
Then you check the sources:
Company A never mentioned write-offs, the model pulled a line from a news article.
Company B’s summary came from a broker note, not the filing.
Company C, the one with the biggest write-off, is missing because the model couldn’t parse the scanned PDF.
It’s structurally unreliable.
This is the point when teams realize the core mismatch:
General LLMs optimise for answering. Financial research requires verifying.
And forcing these models into a finance workflow exposes every architectural fault line underneath.
1. Why Uploading PDFs Doesn’t Fix the Problem
The natural reaction after a few bad answers is:
“Fine, I’ll upload the Annual Report myself. That will force the model to read the right data.”
And it works for a single company, a single document, and a single question.
But real research isn’t a one-document workflow.
The moment you try to replicate what analysts actually do, three immovable walls appear.
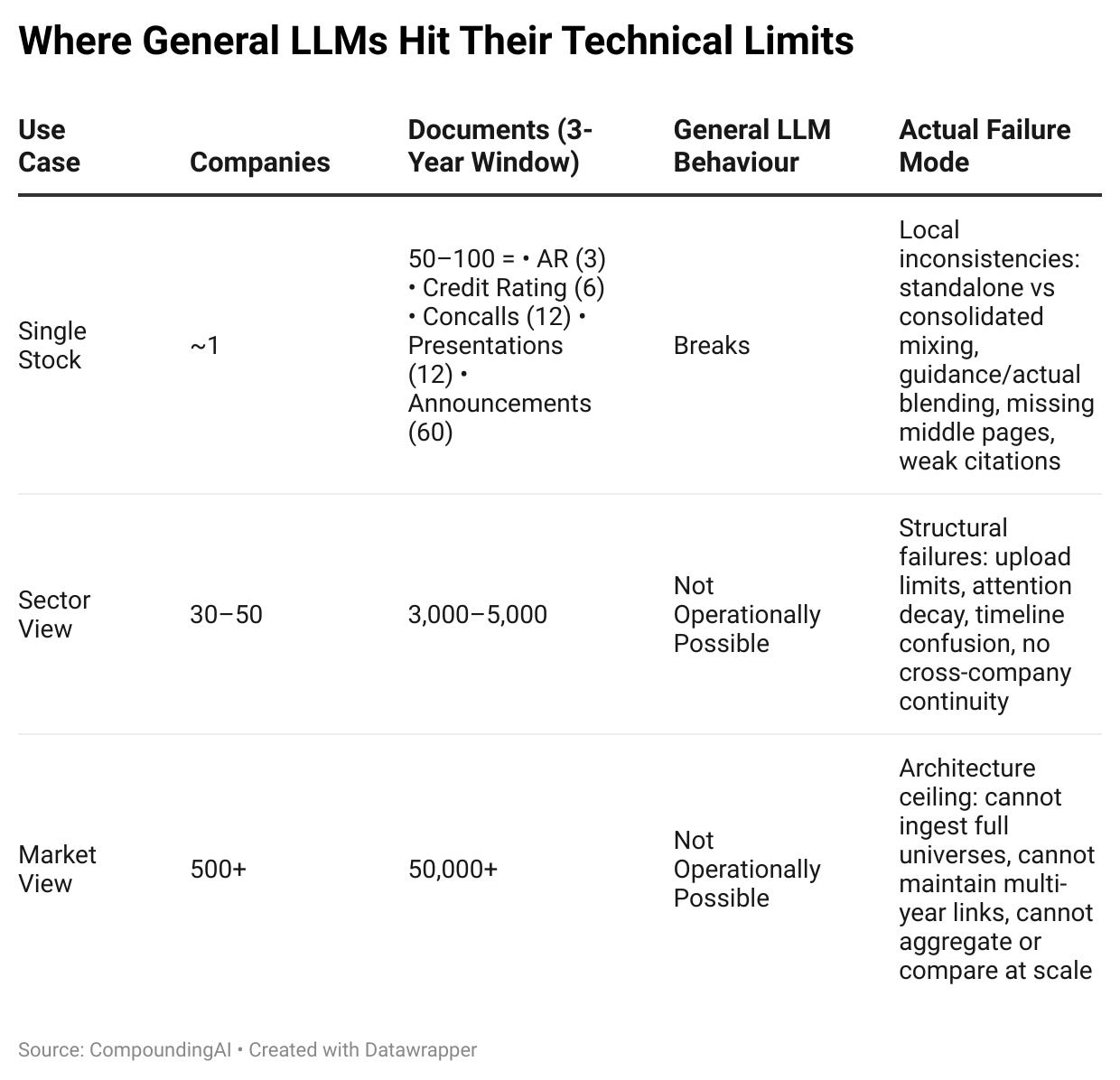
Wall One : The Single-Company Trap (Context Amnesia)
A serious coverage universe isn’t one PDF.
It’s:
4–5 years of annual reports
8–12 concall transcripts
Multiple investor presentations
Credit rating notes
Exchange announcements
Upload everything and ask, general models start blurring.
FY21 commentary blends with FY24 context
Standalone mixes with consolidated
A full year disappears
Guidance slips into actuals
Middle pages effectively vanish (“lost in the middle”)
You’re asking a probabilistic text generator to maintain multi-year continuity across thousands of messy tokens.
It simply wasn’t designed for that.
Wall Two : The Fake Citation Hunt
Even when an answer looks right, verification fails.
You click the citation:
It opens the PDF at Page 1
Or it highlights a paragraph mentioning “Revenue,” but not the number
Or the link points to the wrong document entirely
Or just shows parsed text & not the actual page
If every AI-generated answer still miss verifiability , nothing has been automated — the load has just been reshaped.
Wall Three : The Sector-Scale Collapse
Your actual workflow isn’t about one company — it’s a sector.
To answer the original NBFC question reliably, you need:
20 companies × 10–20 filings each = hundreds of PDFs, thousands of pages.
General LLMs break here for three reasons:
(a) Upload limits
You can upload a handful of documents per prompt or a limited set per workspace — never your full universe.
(b) Memory limits
Even long-context models cannot maintain precise multi-year relationships across hundreds of documents.
(c) No entity-level continuity
General LLMs treat each PDF as an isolated island.
Financial research requires a timeline, not a file list.
At this scale, “chat with PDF” is a good reading tool but not a research system.
The Real Document Footprint in Financial Research
2. The Interface Fallacy : Why “Chat” Doesn’t Map to Finance
Even if hallucinations vanished and citations were perfect, chat still comes with constrains.
It’s not often that analysts work on one-off questions. They execute workflows:
Screening
Deep dives
Tracking guidance
Monitoring disclosures
Updating models
Comparing peers
Preparing desk notes
Chat is linear. Workflows are cyclical, persistent, and stateful.
If you need 20 prompts to recreate a quarterly update, you haven’t automated the work — you’ve turned research into a command line.
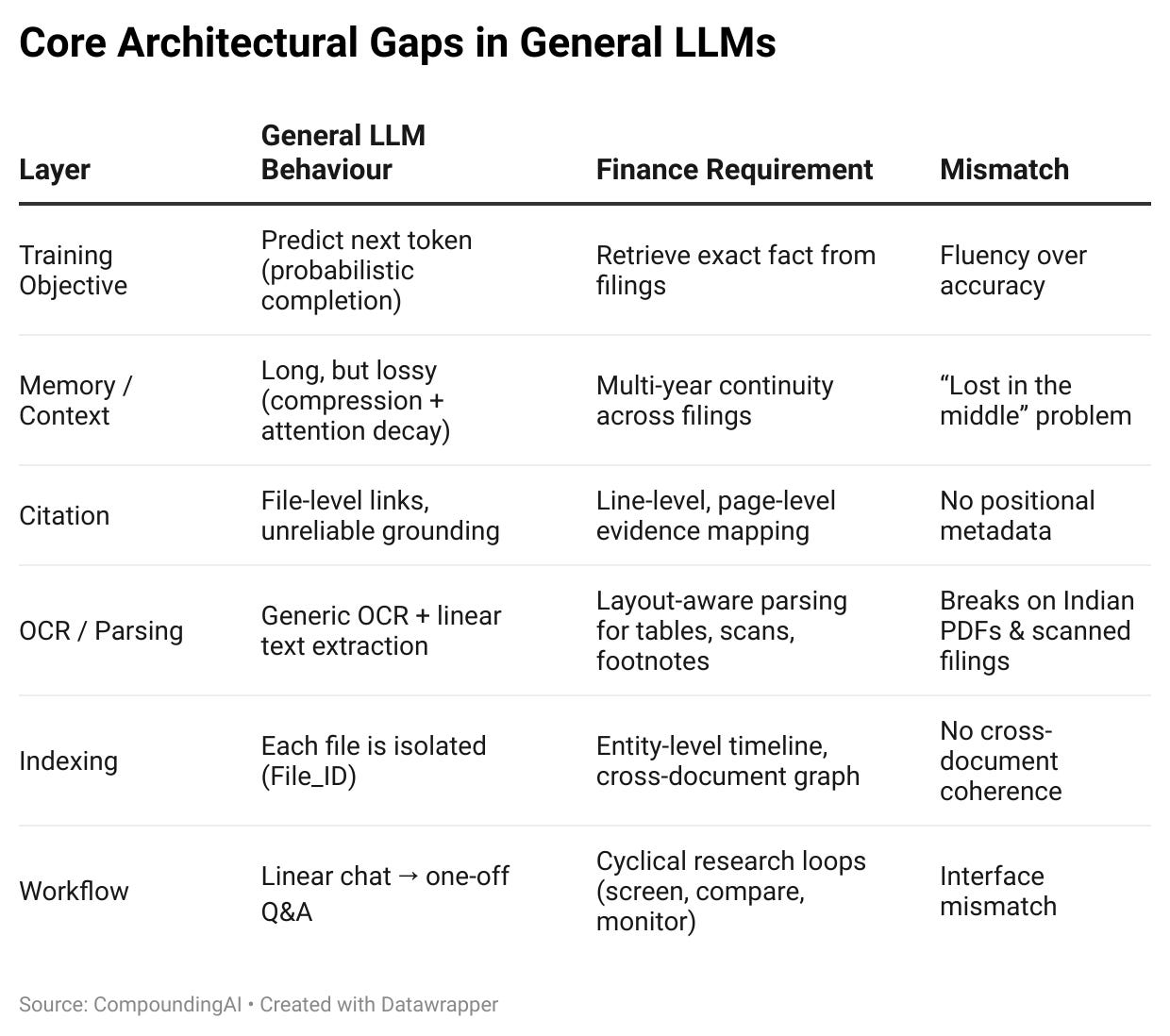
Architectural Mismatch: General LLM Stack vs Finance Stack
3. Under the Hood: Why General LLMs Break on Filings
Most AI failures in finance have nothing to do with “bad prompts.”
They come from deep architectural constraints that make general LLMs fundamentally misaligned with statutory filings.
Below is a breakdown of the actual failure modes.
1. Probabilistic Text Prediction ≠ Factual Grounding
General LLMs are next-token predictors, not fact retrieval engines.
When a number is missing, they generate the statistically likely value, not the true one.
Consequence:
Hallucinations aren’t anomalies, they’re a built-in behavior of the architecture.
Requirement for finance:
A retrieval-first engine that is hard-coded to return “Not disclosed” when a fact is absent, instead of predicting a replacement.
2. Inability to Represent “Negative Knowledge”
LLMs are trained via RLHF to be helpful, not precise.
They avoid null answers because non-answers are penalised during training.
They cannot differentiate:
“The filing is silent on this,”
“I couldn’t find it,”
“Here’s a generic policy from somewhere else.”
Consequence:
Fabricated positives or irrelevant policies appear where regulatory silence is the actual fact.
Requirement for finance:
A system that performs container-level scans (e.g., Notes on Borrowings) and can return deterministic absence-as-information.
3. Attention Decay, Token Limits & “Lost in the Middle”
Even 1M-token models exhibit non-linear attention decay.
LLMs overweight the beginning and end of long contexts and underweight the middle.
Dense financial tables are the worst-case input: high precision, low redundancy, zero tolerance for interpolation.
Consequence:
Upload 2,000 pages → the model confuses years, interpolates missing rows, or merges standalone & consolidated data.
Requirement for finance:
Extract → Normalize → Compare
Facts must be extracted and anchored before reasoning.
4. The Ingestion Bottleneck (80% of the Real Work)
Real filings contain:
scanned pages
misaligned tables
multi-column layouts
nested footnotes
vernacular text
rotated or low-resolution images
Generic OCR + linear parsing collapses on a large share of Indian PDFs.
Consequence:
Downstream reasoning is corrupted before the LLM even begins — extracted data is incomplete, mis-ordered, or missing rows.
Requirement for finance:
A layout-aware parser engineered for financial documents with deterministic reconstruction of tables, footnotes, and headers.
5. Coverage Gaps in Non-Standard Markets
Global systems optimise for standardized filings (10-K/10-Q).
Indian filings vary massively in naming, formatting, templates, and disclosure density.
Many small- and mid-cap filings are scanned or image-heavy.
Consequence:
Critical data is missing, OCR fails, entities are misclassified, and the long tail becomes invisible.
Requirement for finance:
Direct exchange-level ingestion (BSE/NSE) with India-specific parsing rules and entity resolution.
4. The Shift: From Reading to Indexing to Workflows
The fundamental mistake is assuming the unit of work is a PDF.
In finance, the unit of work is:
The Entity (the company), and
The Workflow (screening → deep dive → model update → monitoring)
A finance engine shouldn’t start reading when you ask a question.
It should have already parsed, indexed, structured, and linked the entire market before you log in.
The Takeaway
General-purpose LLMs are extraordinary conversational systems.
But they were not built for:
statutory precision
multi-year continuity
sector-scale ingestion
auditability
null reasoning
workflow persistence
Financial research is built on these constraints.
Until those architectural gaps close, chatbots will remain useful assistants but not research infrastructure.
CompoundingAI is an enterprise-grade vertical intelligence engine that transforms unstructured data into decision-grade insights within minutes, with source-level traceability for confident & auditable workflows across research, risk, and investment teams.
We cut the noise & directly deliver insights.
Couldn't agree more! Such a sharp analysys of the core mismatch. Especially about those architectural fault lines in multi-document workflows. What foundational LLM design shifts do you see overcoming 'context amnesia' for real-world research?